I have decided to write this article to address what I believe to be one of the biggest misconceptions about Bitcoin SV (Bitcoin): the permanency of the data stored on the blockchain.
With the current version of Bitcoin, data storage is achieved through the use of the OP_RETURN opcode. In this article, I will explain why data stored this way is prunable and therefore not guaranteed to remain accessible forever. I will also describe the incentives, protocol restrictions and provide some clues about how this is going to change soon with ways of storing your data with a decent level of permanency guarantee on the blockchain.
In this article I will not dispute whether or not data that is already uploaded will be gone tomorrow, but rather what makes it possible for Bitcoin nodes to delete it if needs be.
I would also like to clarify that all of the information presented in this article is public knowledge. The logical reasoning I tried to follow should not be considered as revolutionary, in fact nothing in this article should be considered as new. Moreover, I have paid close attention to keeping my argumentation as accurate as possible and provide verifiable information. However, in the event I made mistakes, I strongly encourage the reader to reach out so I can publicly address them.
I hope you will find this article interesting, and that it will give you some insights about where we are now and what comes next for Bitcoin, so you can make the necessary adjustments for your project planning, and maybe judge for yourself what the current level of maturity of our Bitcoin ecosystem is.
Introduction
Before I begin, I need to define the scope of permanency. I believe we can all agree that there is very little chance the Bitcoin blockchain survives the heat death of the universe. And with such an infinite scale, it doesn't really make sense to talk about permanency at all... But it also doesn't really make sense either to talk about permanency for a short time scale either. Will your Bitcoin transaction still be accessible after 24 hours? Very likely, yes. Will it still be accessible after 1 year? Probably. Will it still be accessible after a lifetime? Unsure. Will it still be accessible after 10,000 years? Probably not. These estimations are arbitrary and hard to predict. But, in the context of this article I will restrict myself to a permanency evaluated at the scale of several years.
What is easier to measure, however, is the relative data persistency probability (to each other), especially in a context of Bitcoin where data is valued and where the economic system is driven by consensus mechanisms and financial incentives. I will therefore focus on this aspect and talk about the chances that specific type of data will remain accessible on the blockchain relative to each other.
I have also tried to restrict the scope of this article to the specific use case of storing data. With the current version of Bitcoin, many applications use the OP_RETURN opcode to store data, as it is currently the only non-restricted and optimum way of storing data larger than a few kilobytes on the blockchain (which as we will see, is going to change soon on Bitcoin SV). However, you will find that towards the end of the article I have enlarged the scope and what I discuss is not only applicable to OP_RETURN but to any kind of transactions.
Let's first begin and talk about Bitcoin scripts.
What are opcodes?
There is a variety of opcodes as defined by Satoshi Nakamoto for the Bitcoin protocol. Bitcoin scripts are opcodes and their parameters (data) concatenated together which instruct the Bitcoin process to perform a set of operations. For example, the following script instructs Bitcoin to perform the addition operation of 1+2:
1 2 OP_ADD
1and2are data parameters, andOP_ADDis the addition operation.
The above script can also be read in assembly code, which is nothing more than a raw and non-human readable version, but understood by Bitcoin nodes and services.
0101010293
- Our
1becomes0101. - Our
2becomes0102. - Our
OP_ADDbecomes93.
You will notice that white spaces have been replaced by values that correspond to the size of the next data to be read. This is because the process that translates human-readable scripts to assembly knows how to transform these white spaces automatically. Using this trick lifts some of the work we would have had to perform when writing scripts, but makes the human-readable version more comprehensible to us.
The values above are bytes displayed in their hexadecimal encoded format:
0101is two distinct bytes:0x010x010102is two distinct bytes again:0x010x0293is one byte:0x93
Bytes range from 0x00 to 0xFF values (or 0 to 255 in their decimal representation).
When reading the script to understand its meaning, the Bitcoin process evaluates one byte after another from left to right. Each byte corresponds to an operation which describes specific functions to execute.
The very first 0x01 byte tells Bitcoin to place the next byte it will read on a stack. So, Bitcoin creates a stack in its process memory, reads the next byte, which is 0x01, and pushes it on that stack.
The byte that comes next to read, the 3rd one then, is again a 0x01, which again instructs Bitcoin to push the next byte read on the stack (on top of everything else that was stored previously). In our case, our stack now contains 0x01 at its bottom, and 0x02 on top of it.
The next byte read is 0x93, which this time means something else: it tells Bitcoin to pop from the stack the two previous stack items and to return the value of the addition of those two bytes and push it back on the stack (which is now empty). So Bitcoin does 0x02 + 0x01 = 0x03, and stores this result in the empty stack.
You can visualise what is happening on the following website (this is not the only website that emulates Bitcoin scripts, http://learnonchain.com/script is also a good one):
https://siminchen.github.io/bitcoinIDE/build/editor.html
Each byte in a script either corresponds to data pushed on the stack or to an opcode. And just like OP_ADD, there are hundreds of opcodes defined for Bitcoin of many types: Constants, Flow Control, Stack, Arithmetic, Cryptography, etc. OP_RETURN (byte: 0x6a) being one of them. I invite you to refer to the following page which lists the various opcodes defined in Bitcoin: https://en.bitcoin.it/wiki/Script
Scripts are thus the essential component of Bitcoin. They are the instructions that lock and unlock coins. Bitcoin transactions are created around these scripts.
A transaction is a blob of data which contains a set of inputs and a set of outputs. Inputs contain unlocking scripts, and outputs contain locking scripts. Transactions describe how the coins unlocked by inputs are distributed and locked by the transaction outputs. Transactions put one after the other describe how coins move from one to another.
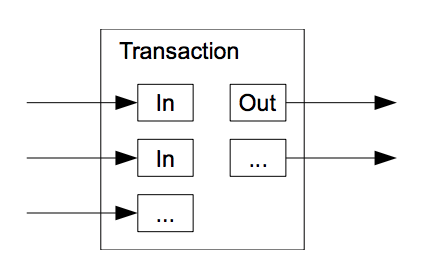
A transaction script that locks coins is also called a puzzle. It is only when this puzzle is solved that the coins are free to move somewhere else. When processing transactions, nodes ensure that the result of the instructions provided by the unlocking script (transaction input) followed by the locking script (transaction output) returns true at the end of the set of combined instructions. When a presumed solution to a puzzle (a script of a transaction input) is found to be invalid and therefore fails to unlock the puzzle, the whole transaction is marked as invalid and is therefore not included into a block. If a block is found to contain an invalid transaction, this block is rejected by other nodes that are incentivised to verify the blocks' validity, so they do not mine a new block on top of a block that is known to be invalid.
In Bitcoin, there are many ways of locking coins in a safe way that guarantees only the intended recipients can unlock the coins. The most standard way is through the use of the following locking scripts:
- Pay To Public Key Hash (P2PKH):
OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG, which requires a valid<sig> <pubKey>(signature along with a public key) to be unlocked. - Pay To Pubkey (P2PK, obsolete):
<pubKey> OP_CHECKSIG, which requires a valid<sig>(signature) to be unlocked. - Pay To Script Hash (P2SH).
- Multisignature (multisig).
As you could have guessed, there are pros and cons in using some combination of opcodes, or others, to lock coins. For example, some are insecure, others are not. The important part to understand here is that Bitcoin's protocol was created to allow everyone to design their own locking and unlocking script mechanism. The ones I have enumerated above are only the ones people have come up with and decided to use as the established standard ways to move coins for payment purposes.
Now that we understand scripts and transactions, let's dive into the opcode we are interested in: OP_RETURN.
What is OP_RETURN?
OP_RETURN is a specific Bitcoin opcode, which, when read, instructs the Bitcoin application processing the transaction script to drop out of statement. This means that when the Bitcoin process that decodes and evaluates the script encounters OP_RETURN, it will just drop the execution and will return a value that could be equal to true, false or fail. In the case of BTC (Bitcoin Core), this instruction returns fail by default. In the case of Bitcoin SV (Bitcoin), this behaviour will be changed. I invite you to read Steve Shadder's article about it here:
The return of OP_RETURN – roadmap to Genesis part 4
Our concern, in the context of writing this article, is not really what OP_RETURN returns, but how transactions that use it are considered by nodes.
At the present time, the transaction output scripts (those that lock coins) that use OP_RETURN are outputs that are provably unspendable when they default to either fail or false. Or are provably immediately spendable by anyone when they default to true, in this case miners could instantly collect the coins by spending such transaction outputs that they discover. For the purpose of writing a comprehensible article, I will now refer to OP_RETURN transaction outputs as transaction outputs that are provably unspendable (even for transactions that are immediately spendable).
Let's see now why the fact that OP_RETURN transaction outputs being provably unspendable holds no value to miners after the transactions are included inside blocks.
The value of OP_RETURN transaction outputs
In Bitcoin SV, OP_RETURN is used to store data. The OP_RETURN opcode precedes any data that users wish to store. This has the advantage of making this data irrelevant as it is not evaluated (because of the drop out of statement after encountering OP_RETURN). However, this data being a component of the transaction output, it cannot be stripped out nor changed – the reason being that transaction outputs in their entirety are part of the transaction hashing and signing process when standard unspent transaction outputs are spent. More about it later. So, altering the data would automatically make the transaction invalid and the transaction inputs would need to be rehashed and resigned by the emitting user.
The way OP_RETURN is currently used to store data in transaction outputs is through simple scripts: OP_RETURN DATA... or even OP_0 OP_RETURN DATA.... I will consider those for the rest of my article, but my argumentation remains valid so long as the transaction outputs remains classified as provably unspendable or already spent.
The case of nodes
Miners (which are nodes) do not only collect block rewards, they also collect transaction fees by including valid transactions inside blocks. Which is one of the reasons why miners have the incentive to keep stored locally a maximum of unspent transactions. The purpose being to collect a maximum of transaction fees. This will become more and more important because block rewards are running low, which should push miners to optimise their operations.
As we have explained before, locked transaction outputs await to be unlocked by transaction inputs of new incoming transactions. Once a transaction has all its outputs spent, the transaction is classified as spent. And, as you can understand, a transaction that has all its outputs spent is a transaction that doesn't hold any potential to make miners earn fees from it anymore. Which means, spent transactions no longer hold an instrumental value (for this context). The data itself may, however, still hold an intrinsic or subjective value to the eyes of the node operator, but let's not digress. Our focus is to understand what holds the Bitcoin economy together and its mechanism of incentives in the context of mining to earn transaction fees.
After blocks are mined, they are broadcasted across the Bitcoin network to all nodes, which validate them and store them on their local storage. This pile of blocks stored locally is what constitutes the blockchain.
But piling blocks consumes disk storage... Currently above 160 Gigabytes.
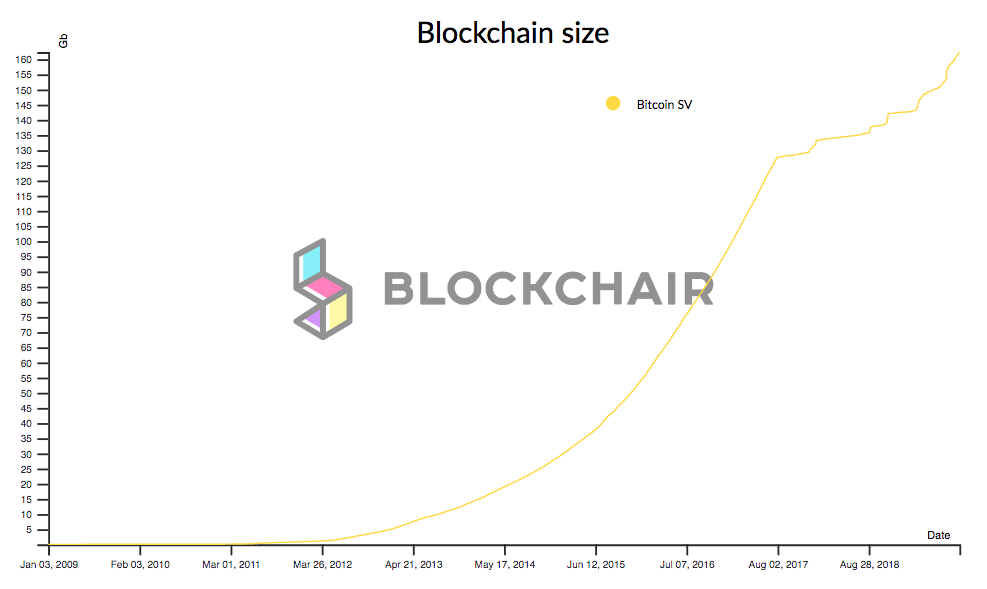
Satoshi Nakamoto thought of this issue during the design of Bitcoin. And, instead of forcing nodes to keep transactions that have already been spent, nodes have the ability to prune spent transactions. The Bitcoin white paper provides a description of this feature.
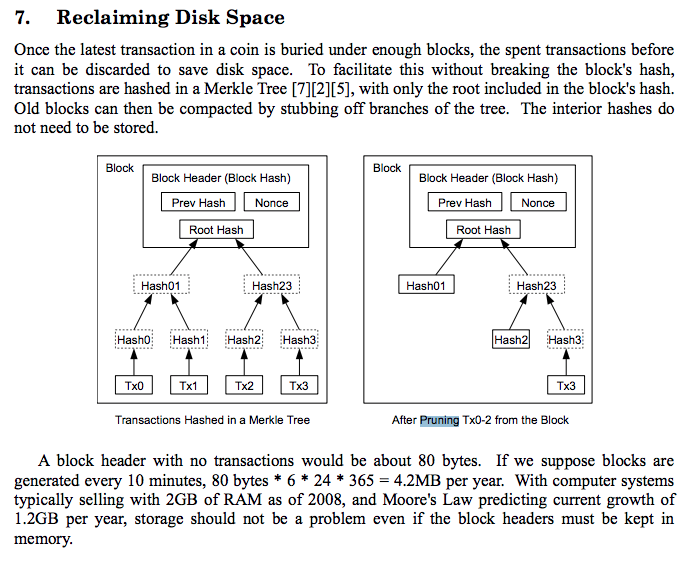
Pruning spent transactions does not alter the functioning of Bitcoin. It does not alter the validity of blocks and does not alter the verification of the whole blockchain. Nodes that have such partial copy of the blockchain can still operate properly, they can still verify blocks, mine blocks, and validate mempool transactions. More about it later in the article. For now, you only need to trust that Satoshi's design isn't broken.
With such pruning design, transactions (as a whole) can be pruned when it is provably verified that there will never be a valid incoming transaction that can spend any of those transaction outputs. But this is also the case when all transaction outputs are provably unspendable transaction outputs. Which means that spent transactions that contain our OP_RETURN transaction outputs can also be pruned. There are even comments in the Bitcoin code about this aspect:
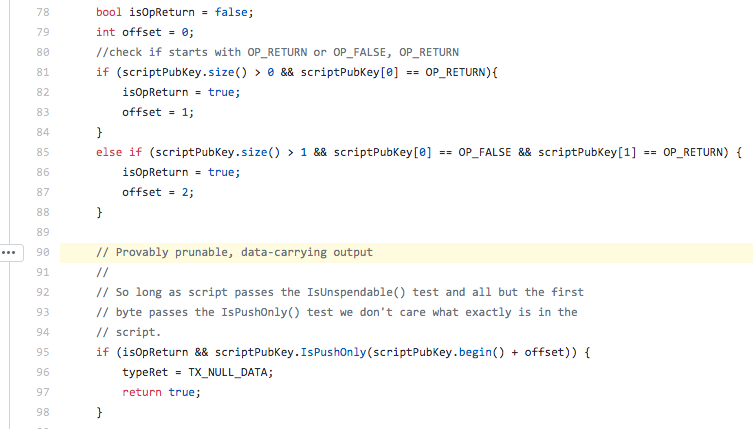
Provably prunable, data-carrying output
So long as script passes the IsUnspendable() test and all but the first byte passes the IsPushOnly() test we don't care what exactly is in the script.
So, what does it mean exactly that nodes can prune spent transactions that contain OP_RETURN outputs?
It means that nodes can, if they choose to, delete your transaction from their local copy of the blockchain. Which means that the transaction will no longer be available on their node, and the data it originally held will also not be available anymore from the node. It also means that if someone joins the network and wishes to download a copy of the blockchain from that node, the blockchain copy retrieved will be partial and the missing transactions (if required) will need to be fetched from some other nodes... if any kept them...
Do nodes have an incentive to prune OP_RETURN transactions?
It depends on how they value this data. And as we have seen before, in the context of "return on investment with transaction fees", the answer would be yes, they do – spent or unspendable transactions that take up disk space at a cost are stored at a loss.
Although the cost of storing data is decreasing over the years, it will not reach zero.
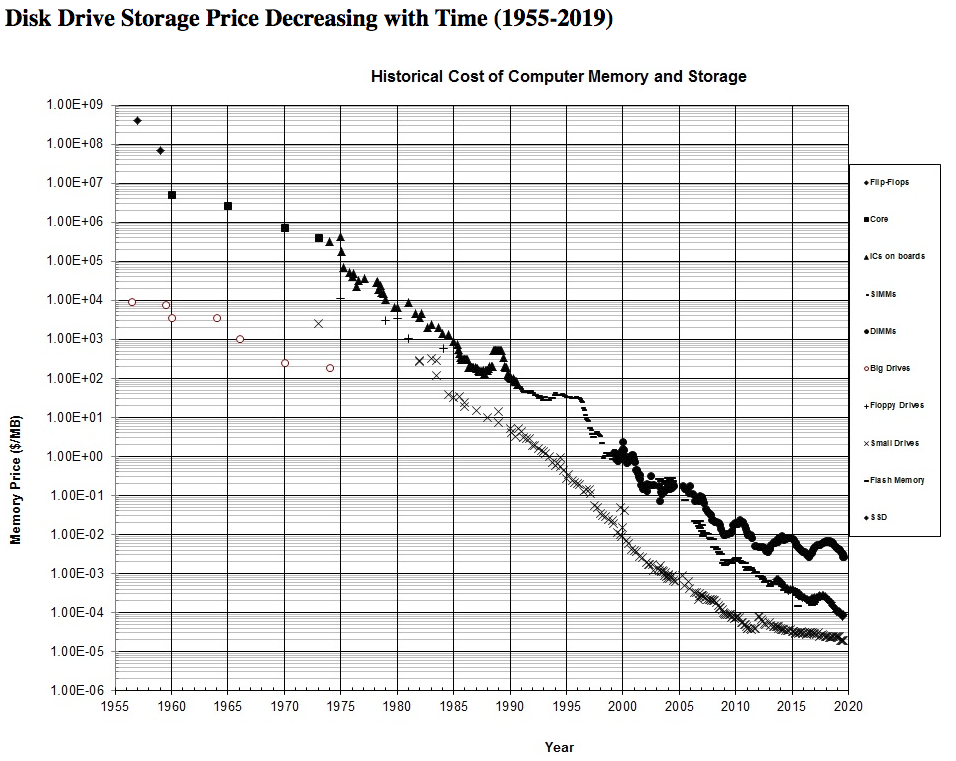
We could argue on the intrinsic or subjective value of certain OP_RETURN data just so that we could also argue on the cost of storing so little data, which, if taken individually would be an insignificant cost for node operators. However, the biggest picture is long-term and volume. Especially when it comes to Bitcoin SV, where the vision is for businesses and applications to store data, lots of data! Therefore, over time and at the rate the blockchain grows, nodes will eventually realise that the storage of such data will become a non-negligible cost. Node operators will therefore be incentivised to prune some (if not all) of the spent transactions and transactions that are provably unspendable. Which includes OP_RETURN data.
The case of users and businesses
This section addresses the intrinsic and subjective value of the data stored by users and businesses. Which is similar to the valuation node operators would attribute to the data contained in OP_RETURN transaction outputs.
So, I recently created a poll on Twitter about how users and businesses value the data they have stored on the blockchain so far. And I was surprised to discover that half of them highly value the data they store on the blockchain.
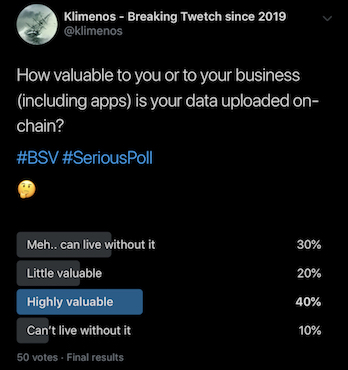
This is how I have interpreted the poll results:
- Half of the users that highly value their data will be very unhappy if node operators decide to start pruning their data.
- Half of the users would not mind if their data is pruned by nodes. Which also means nodes would have even more reasons to prune their data.
I personally do not really see a future where Bitcoin node operators would invest time and effort to implement highly selective pruning capabilities and where users would have a say about what is to be kept or not. But anything is possible... Also, while anyone is free to join the network and run a full node, this does not solve the problem, especially when the rest of the network is not incentivised to store the data permanently.
Once nodes will start pruning data to free some space because they have a strong financial incentive to do it, apps that still use OP_RETURN will be forced to save their own local copy of the blockchain to preserve all this data. Then you might think... how does that make it any different from using a regular centralised database? There are positive answers to this question, but that would be a topic of discussion for another article.
Let's see how users can make their transactions more valuable to the eyes of miners...
Making transactions more valuable
For most of the transactions that have been spent already, it might unfortunately be too late to make them more valuable now.
For transactions that have not been spent – meaning they have at least one unspent transaction output - you might be in luck... at least for a little while... until nodes implement a more granular and advanced pruning mechanism that prunes individual spent or provably unspendable transaction outputs. Which, in short, means that leaving an unspent transaction output does not guarantee the permanency of your OP_RETURN data. Let's see why in detail.
The white paper in chapter 7 (shown above already) describes that transactions can be pruned. And the current implementations of Bitcoin (to my knowledge) make it so that transactions in their entirety can be pruned. But not the white paper nor the implementation mention that individual spent transaction outputs (or provably unspendable outputs) can also be pruned safely without altering the functioning of nodes or altering the validity of the unspent transaction itself (which contains outputs that have not been spent yet). As we have seen before, unlocking transaction puzzles only involve the previous transaction output, which is needed by the spending transaction to unlock the coins. The rest of the transaction and its outputs are not involved in this process or by the process that validates the transaction.
Implementing pruning for individual transaction outputs would involve writing some code to customise the pruning functionality of Bitcoin. It can be done in a safe manner so that it doesn't interfere with the validity and validation of the non-pruned transaction outputs when they are spent. The way this can be achieved is by signing the new transaction hash with a key owned by the node operator who wants to guarantee the change (pruning) was performed in a controlled manner, and auditable fashion. Using this technique, the change can be validated later on by verifying that the signature of the new hash is valid. I will not detail the implementation any further as this is not the topic of this article. But you can bet that if such implementation was made available, nodes that require a more efficient pruning implementation would jump on this opportunity to save more disk space, which will help them reduce their cost of storage bills.
So, leaving an unspent transaction output is definitely better than leaving none, and your data might persist for a little while. But it is still not good enough. What would be great is if we had a way to make our transaction outputs that contain our data spendable. This way, nodes would be forced to keep a copy of the script that contains the data in the hope that someone one day spends the transaction; so they can validate the transaction and therefore the new incoming block that includes it, but also so that they can collect the fees if they mine the corresponding spending transaction.
The power of signatures
OP_CHECKSIG, and similar signing opcodes of the same cryptographic class, is an opcode that signs a hash of a crafted copy of its own transaction blob. This signing process requires to incorporate the original unspent transaction output (UTXO). Meaning that for a node to validate a transaction that includes OP_CHECKSIG, the node also needs to have a copy of the original UTXO stored somewhere in order to validate the unlocking script present in the transaction that spends the UTXO. In other words, nodes can't easily get rid of UTXO scripts (or at least not entirely, cf. OP_CODESEPARATOR), and this is exactly what we are looking for.

This process is spread across the Bitcoin code, for transaction validation and raw transaction creation through RPC. I found it easier to locate part of it in the RPC raw transaction processing source code.

How does that help us?
One (bad) way of storing data is to embed data within the <pubKeyHash> in the transaction output. Keeping the same length and format is necessary. Nodes will eventually hardly be able to tell if the <pubKeyHash> present is a valid public key hash or if it is a crafted one which has the purpose to carry custom user data (unspendable). OP_CHECKMULTISIG can also be used and allows for more user data to be stored - currently 15*33 bytes.
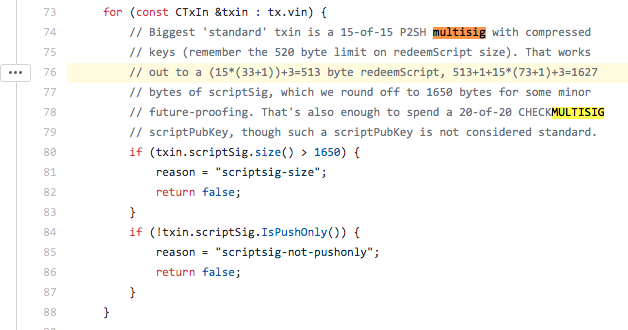
But this isn't a practical way of storing data. It is quite costly and it can be argued that nodes could detect if messages are passed instead of legitimate public keys, which would indicate the transaction is likely unspendable. The use of encrypted messages with algorithms such as AES could help mask this, since the data would look random just like ECDSA signatures. But still, this remains very impractical.
One solution
How about we just push the data on the stack, then drop it and resume the process of a standard script. For example:
48656c6c6f20776f726c6421 OP_DROP OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG
The above locking script instructs to push data on the stack at some point, which is the data that I want to store on the blockchain:
48656c6c6f20776f726c6421which decodes toHello world!.OP_DROPis the opcode that removes the data I just pushed on the stack.- The rest is a classic P2PKH script.
That custom script is equivalent to the short version below:
OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG
The only difference is that the signatures required to redeem them (used by transaction inputs) will differ. This is because, as we've seen before, the signing process embeds our script as a whole – it preserves and uses our data to generate the signature. Which is why nodes are required to keep the UTXO script unaltered (and not prune it) in order to validate the signature provided from a transaction that spends it.
In order to store more data than just a small "Hello world!" string, the following additional opcodes that push data on stack can be used:
OP_PUSHDATA1- Pushes up to 255 bytes.OP_PUSHDATA2- Pushed up to 65,535 bytes.OP_PUSHDATA4- Pushes up to 4,294,967,295 bytes ~ 4 Gigabytes.

Similarly, if I wish to store a picture with a good level of permanency guaranteed, I could broadcast the following UTXO:
OP_PUSHDATA2 MY_CAT_PICTURE_DATA OP_DROP OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG
Where MY_CAT_PICTURE_DATA is the raw data of my cat picture.
I could also use existing (but adapted) unwriter's B:// protocol with OP_PUSHDATA and get a decent structure for my data to be used by my applications.
OP_PUSHDATA4 B_PROTOCOL_DATA OP_DROP OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG
You will notice I have not mentioned the bytes that correspond to the number of bytes pushed on stack. As explained earlier in the article, this is because, when converting the human-readable scripts, the white spaces are converted to byte sizes (when this is needed).
The beauty of using OP_CHECKSIG lies in the fact that those scripts are spendable. Another interesting advantage is that transactions that use this opcode can also be spent at any time by the recipient. The recipient could be an application or a user that could spend the data when he/she/it decides to unlock the coins and therefore spend the UTXO, so nodes operators are informed that the transaction output (and therefore the data) is now prunable.
Storing data without involving signatures
I cannot think of other straightforward ways to store data while ensuring nodes remain strongly incentivised to keep it to validate potential spending transactions and collect fees (if mined).
If you decide to design your own permanent data storage script, you will need to satisfy the following:
- Ensuring nodes cannot guess the transaction output is unspendable (or very likely unspendable).
- Ensuring the integrity of the transaction output is required and preserved to validate the spending transaction.
If you only satisfy point 1., then dropping the data means that the node could just prune/replace the data of your script and keep the rest - this, without altering the script's original general instructions: using custom pruning at a granular level, which again, can be performed in a secure manner that doesn't interfere with the validation of the transaction output (signing the hash of the new script, similar to the technique used before).
You may be able to get away with point 2. if the data is part of the script's puzzle set of instructions. But I am not sure if this would be really practical or even achievable for big data.
If you only satisfy point 2., then your transaction output is guaranteed to be prunable.
Broadcasting custom transactions
Now that we know what kind of custom transaction output script we wish to broadcast, let's find a tool to try it!
Let's find tools on Google
I have searched, for quite a while... most tools only provide ways to create standard transactions. For non-standard transactions I found this tool:

But it isn't as straightforward to use for our purpose, since we don't really want to deal with transaction inputs manually...
You might begin to wonder why after 10 years there are still so few tools for non-standard scripts... We will see why a bit later.
Let's try to use Money Button
If you have read my previous articles about the WeiTch protocol, you already know I like reversing things, especially when the application's front end poses no resistance and provides all the features I need to repurpose and hack its functioning.
In the case of Money Button, which is a web-based Bitcoin under the control of users, it is quite straightforward to edit the output scripts we wish to use. In fact, this is the main reason why Money Button is the prime choice of web application developers, because it allows building transactions with custom script outputs for users to swipe, all of it effortlessly.
We can find documentation about how to achieve it on Money Button's website:


All we have to do then is to register a Money Button account and create a dummy web page that contains the following source code for example:
<script src="https://www.moneybutton.com/moneybutton.js"></script>
<div id='my-money-button-1'></div>
<script language='javascript'>
const div1 = document.getElementById('my-money-button-1')
moneyButton.render(div1, {
outputs: [{
script: 'OP_FALSE OP_RETURN 31394878696756345179427633744870515663554551797131707a5a56646f417574 48656c6c6f20776f726c6421 746578742f706c61696e 74657874 6b6c696d656e6f735f68656c6c6f5f776f726c642e747874',
amount: '0',
currency: 'BSV'
},
{to: 'klimenos@moneybutton.com', amount: '0.00005', currency: 'BSV'}]
})
</script>The button that will be displayed on the page will be the following:
When swiped, this button broadcasts a transaction that contains three outputs of which two were defined in the JavaScript code we customised:
- TXO_1 (with 0 BSV locked):
OP_FALSE OP_RETURN 31394878696756345179427633744870515663554551797131707a5a56646f417574 48656c6c6f20776f726c6421 746578742f706c61696e 74657874 6b6c696d656e6f735f68656c6c6f5f776f726c642e747874 - TXO_2 (with 0.0005 BSV locked): A standard P2PKH paid to one of Klimenos' Bitcoin addresses that is fetched through his klimenos@moneybutton.com Paymail.
- TXO_3 (not displayed): A standard P2PKH for the change, which is used when the sum that transaction inputs unlock is bigger than the total amount spent including transaction fees.
The TXO_1 and TXO_2 that we have instructed are human readable, and as you have noticed, it was not required to enter anything more. This is because Money Button takes care of automating the rest of the transaction construction process. And while we had to craft the script of the first output manually, you will notice that Money Button has made significant efforts to make our life easier for the second transaction output, so we don't have to find the recipient's address and build the script manually. This automation is greatly appreciated by developers.
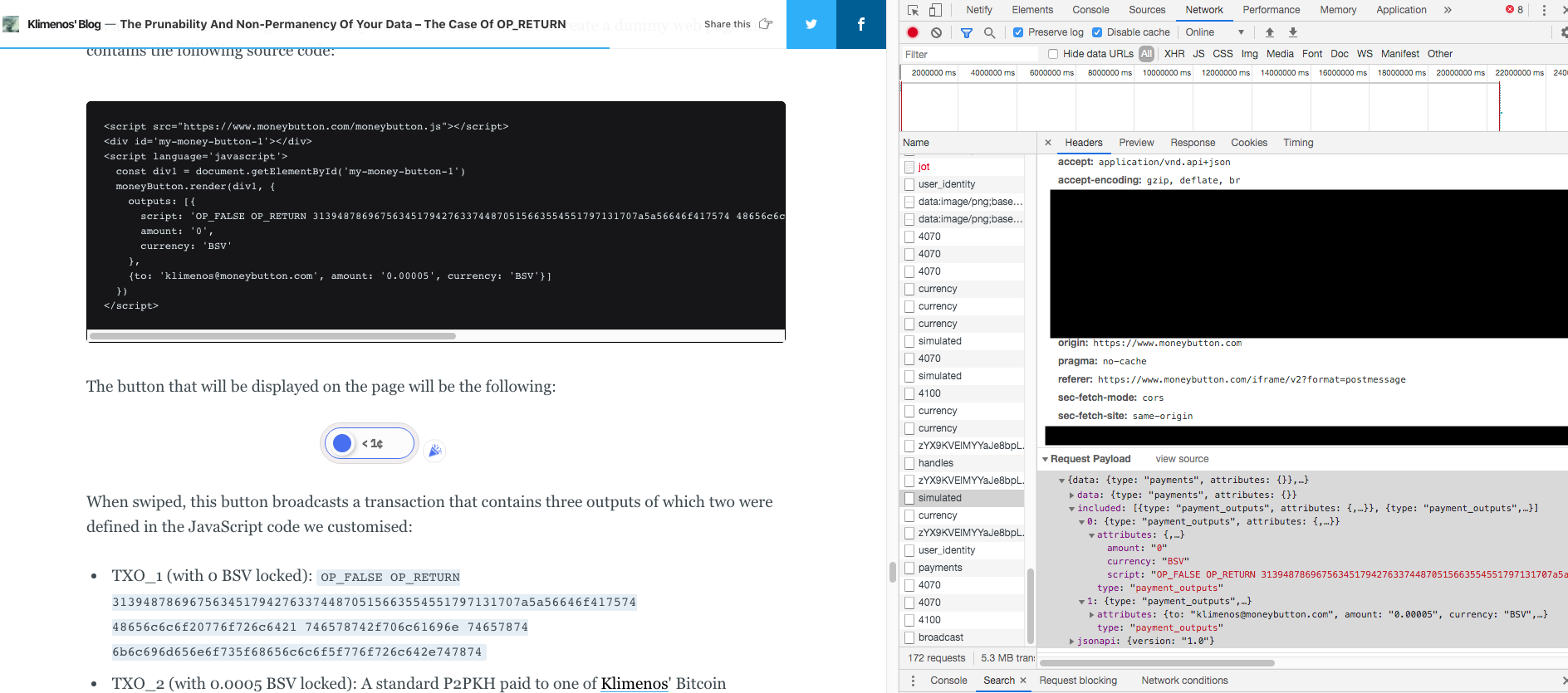
If you open Firefox Developer Tools or Google Chrome DevTools and switch to the network analyser section, you will notice two interesting requests submitted by Money Button:
- The simulated request, which sends the human-readable scripts to Money Button for validation before the user swipes the button. Money Button's server either responds that the transaction is valid or that it isn't. If it is valid, the server will return to the user everything needed to construct the final raw transaction.
- The broadcast request, which sends the final raw transaction to Money Button's node to broadcast it on the Bitcoin network. This request is sent only after the user swipes the button.
After swiping the transaction, we can find it using a block explorer:
Or, because the embedded OP_RETURN data uses the B:// protocol (I'm sure some of you already noticed), it can be directly visualised on bico.media: https://bico.media/b://9cb55b2bfb6035aa243d1ea51bd05896ed834dd54fbeadc381e51c1d4fbecf72
But, like we said before, we don't want to use OP_RETURN to store our data because it doesn't provide a good level of permanency. So let's craft a push data transaction output script instead, followed by a standard P2PKH, since as we discovered before, it provides a much higher level of non-prunability:
<script src="https://www.moneybutton.com/moneybutton.js"></script>
<div id='my-money-button-2'></div>
<script language='javascript'>
const div = document.getElementById('my-money-button-2')
moneyButton.render(div, {
outputs: [{
script: '48656c6c6f20776f726c6421 OP_DROP OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG',
amount: '0.00005',
currency: 'BSV'
}]
})
</script>Our output script that stores data is the following:
48656c6c6f20776f726c6421 OP_DROP OP_DUP OP_HASH160 6cd91d791372e0b0660dea04e8dd84fc65c2c289 OP_EQUALVERIFY OP_CHECKSIG
You will recognise the "Hello world!" pushed on the stack, followed by the OP_DROP operation. The rest is a P2PKH which locks 0.00005 BSV in one of my wallets. The button is the following:
If you see the network activity for yourself, you will notice the transaction simulation does not complain, so the script appears to be valid... But after we swipe our button, we have an issue with the broadcast request!
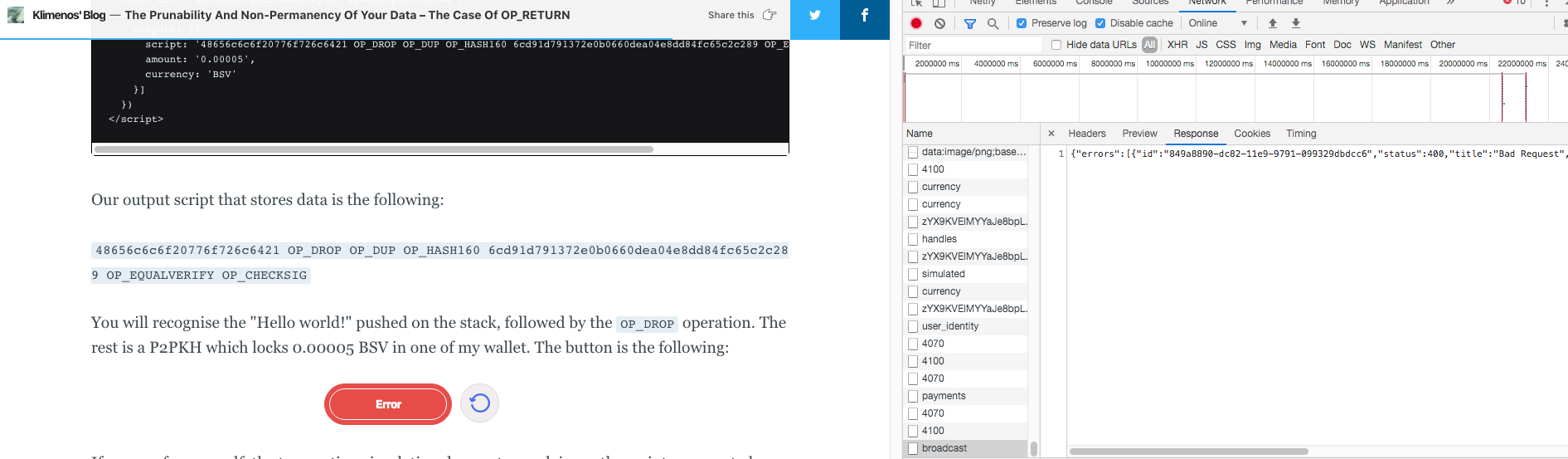
This is what the Money Button server responds:
{"errors":[{"id":"849a8890-dc82-11e9-9791-099329dbdcc6","status":400,"title":"Bad Request","detail":"Failure during transaction broadcast. Transaction may be invalid."}],"jsonapi":{"version":"1.0"}}
Maybe if we manually broadcast our transaction using a different node, that would work...
Broadcast the transaction with ElectrumSV
We can find our raw transaction from the Money Button broadcast client request body and pass it to ElectrumSV.
This is our raw transaction:
0100000001dcf126342f71cadb1d9a6e38802c34595ccd731771fa39d4608b99e06d5cb9c0020000006b483045022100895a7e73413fe28a02eb2fa23d4f143a262df34ab1f46a2fa61bb7e89c357ecd022009b519d7d941be4e8104674e8dffb3eaaab4b1256f1918e2926eef408f135d62412103d61376ae8b56f9d789b1392ae8957f235b49120197e9601baa1eb524086a46d3ffffffff028813000000000000270c48656c6c6f20776f726c64217576a9146cd91d791372e0b0660dea04e8dd84fc65c2c28988acb8140100000000001976a914dca370c40348d61ee0b8198f41c977ff0fd64c6b88ac00000000
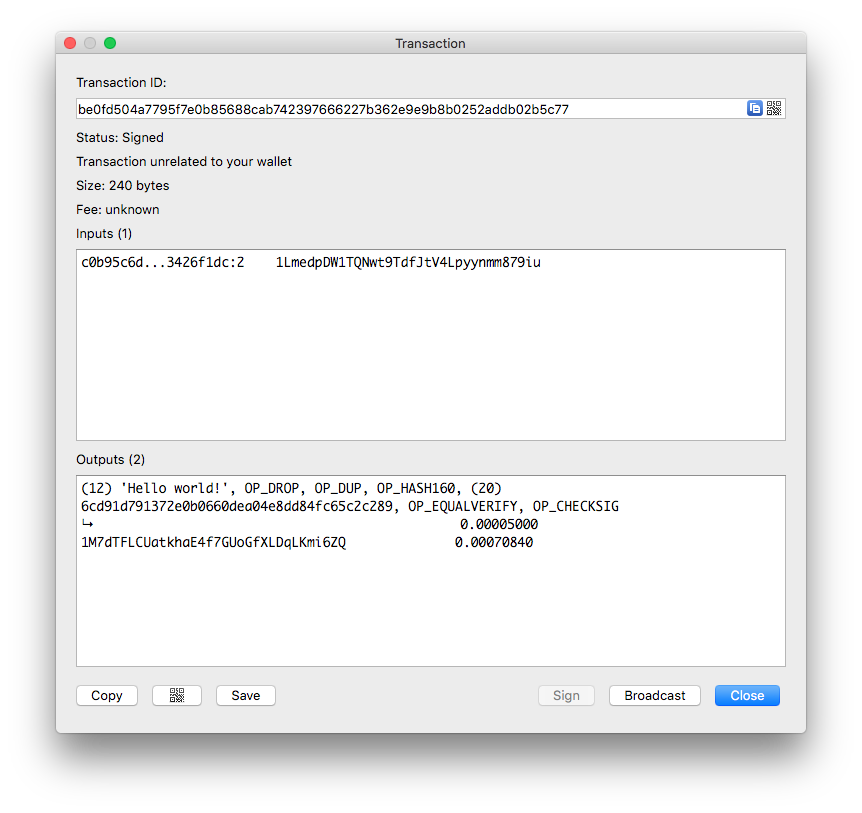
The result after broadcasting the transaction to a random ElectrumSV node:
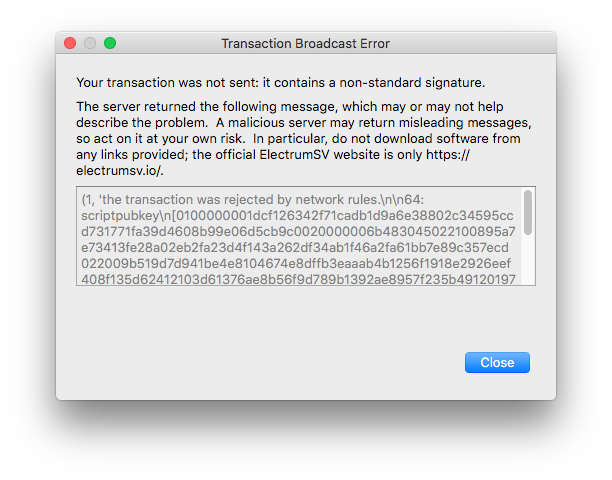
Still no luck! This appears to be the same issue we had with Money Button. Could it be then that the restriction is enforced on the Bitcoin node software itself, despite the Bitcoin protocol allowing custom scripts?
Remember when I said there are two types of scripts: standard transactions and non-standard ones? Well, it turns out developers have implemented artificial restrictions in the code to prohibit the broadcast and mining of non-standard transaction. Which means, Bitcoin at this stage can only be used to spend coins and store limited amount of data in a prunable fashion... nothing else!
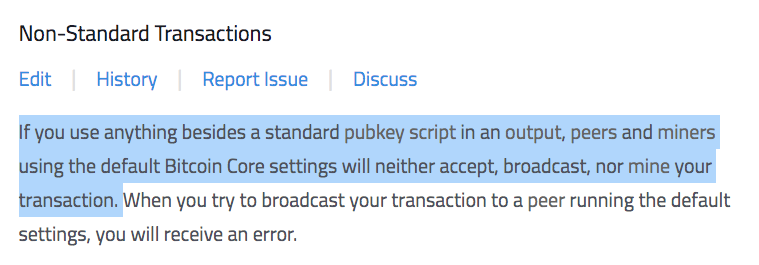
This enforcement is present in the Bitcoin SV v0.2.1 source code:
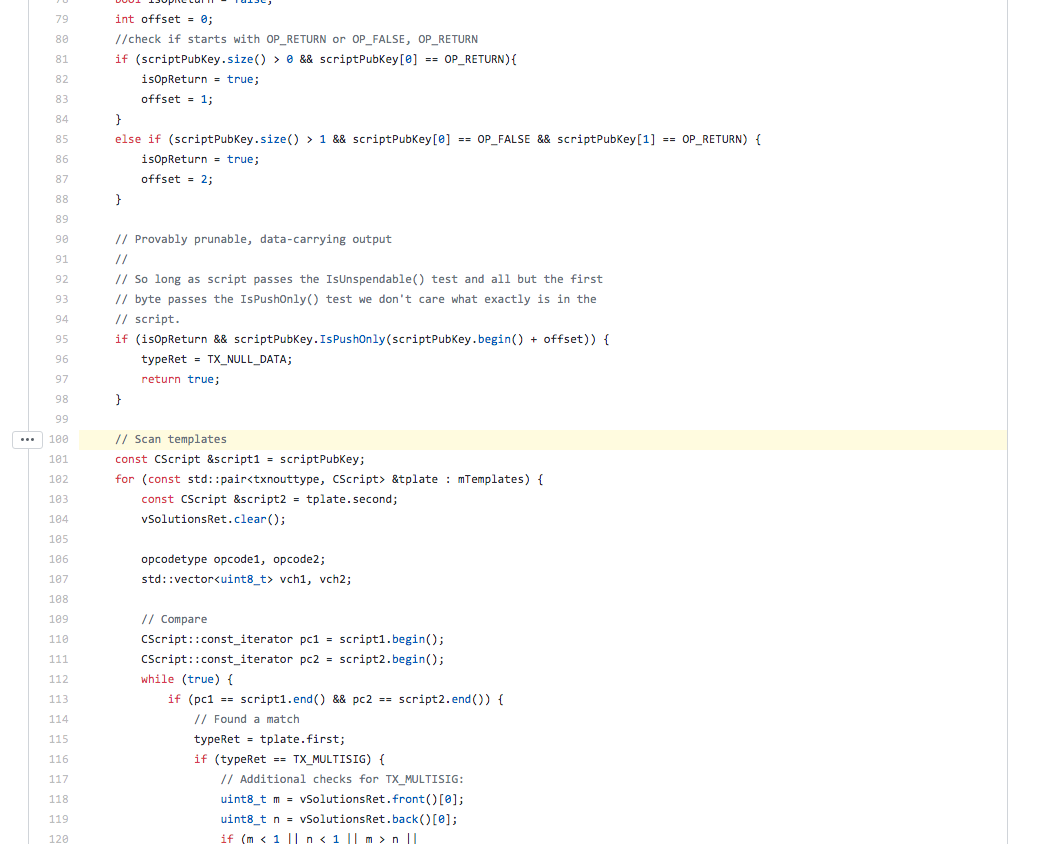
Well, I guess we are stuck with our prunable OP_RETURN data for now then...
When code is law...
When I saw the above code, this is what I thought developers might be thinking:
We are anarchists, but we don't want the government to regulate Bitcoin. And because we don't trust anyone but ourselves, we decided it was better that nobody stores any data on-chain... We make the law now about what users can or cannot do with Bitcoin. Instead of having the market decide what purpose Bitcoin serves, we enforce through code that the only purpose is payments using our only specific standard transactions. Anything else users want to do with Bitcoin is rejected by our code. We are the Bitcoin Core devs, we are your masters, we decide what is good for you, our code is law now.
What does it mean? Why do this? There are several reasons to it, some being that flaws were found with custom scripts, but even that doesn't justify why after 10 years of Bitcoin, users are still restricted to using a narrowed set of standard scripts... The reason is somewhere else, and clues can be found in the code and its comments.
In the real world, there is Law and Freedom. Freedom gives people the power to act, speak and think as they wish. Law is in place to disincentivise people from using that freedom to cause harm in any way, shape, or form. Such system also applies to Bitcoin. Bitcoin was initially designed to welcome Law in its incentive mechanisms. But developers, instead of welcoming law to regulate Bitcoin and help prune illicit transactions, decided to become the lawmakers themselves by making their code the Law. Do you see the irony?
Incentives, consensus and the Law
Bitcoin by design allows international laws to take action and force consensus to prune any transaction or, at a granular level, any transaction output deemed illegal, whether or not the transaction is spent. Such mechanism is not in the code, but it can be implemented. Bitcoin's design allows such implementation without breaking anything and especially without altering the Bitcoin protocol. The only thing that would need to be taken care of, and which is why I mentioned international laws, is the network consensus. Let's see why below.
Incentives and consensus
A good portion of the mechanics that disincentivise node operators from misbehaving is: financial incentives!
Nodes, for example, could potentially blindly trust incoming blocks that contain transactions spending outputs they've decided to prune on their own. But that would mean they have no way of telling if the incoming blocks are valid or not. Which means they would take a risk of mining on top of invalid blocks, and therefore they would lose money (energy spent mining for nothing). We can also think of scenarios where attackers would push this further by broadcasting invalid blocks to other miners and therefore ensuring miners behave, but while this isn't really necessary this is yet another good reason for nodes to ensure they validate blocks because it is in their own financial interest.
Now, if among the network there is a general consensus to reject certain transactions (like we have seen enforced in the code with non-standard transactions), validation is no longer an issue. Nodes will be able to safely reject blocks that contain specific types of transactions (agreed to be invalid by the network) at no financial cost. Because if a block is ever found to contain a rejected type of transactions then the majority of nodes would reject it (because of the consensus). Nodes would therefore still continue to mine blocks and just ignore this invalid block.
In the specific case of unspent transactions, a network consensus could also ensure that they remain locked and never spent. That would mean establishing a blacklist of unspent transactions. Or, at a granular level, a blacklist of UTXOs. If agreed by consensus that would mean that miners that decide to mine spending transactions of blacklisted UTXOs would fork off (likely produce orphaned blocks). The rest of the network, which is the majority of nodes, would reject those blocks and continue to mine on the main chain. And because those transactions or UTXOs are blacklisted, they respectively fall in the category we discussed earlier in the article of prunable transactions and prunable transaction outputs.
The above examples should have convinced you that none of the data stored on the blockchain can be said to be forever accessible, no matter the script mechanism used to store it. Consensus always wins in the end, which also makes Bitcoin law-abiding.
Bitcoin, law-abiding by design
The way Bitcoin was designed makes it so that the only thing that ultimately truly matters in the end is the trail of evidence. This is because of the following properties:
- The Bitcoin block hashing algorithm is designed to hash the header of the block only. Therefore, the validation of previous blocks' integrity goes through block header hash validation.
- The Bitcoin Merkle tree (hash tree of the transaction hashes) has its hash root included in the block header. Therefore, the validation of transactions buried within previous blocks goes through hash validation using the Merkle hash root.
The trail of evidence (hashes) is what really matters for the Bitcoin protocol to function. The content of the transactions does not matter. This content is only ephemeral for the need that node operators and users have of using it.
Hashes could be considered as immutable (more than any transaction data) because they are required for the functioning of Bitcoin. Without this property, the Merkle tree does not work. Without this property, the block hashes cannot be verified.
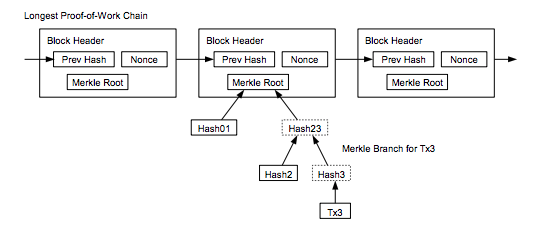
With the above specificities and in order to validate the integrity of previous blocks, a node operator would not require the transaction's content at all (because this part was covered when the block was mined and included on the blockchain). For transactions, the only thing that matters for node operators is to keep on record the block headers (which contains the Merkle hash root) and the Merkle hash leaves that lead to the transaction hashes (those that have not been pruned).
Like we've seen before, nodes keep the transaction's data because they are financially incentivised to do so, which is driven by consensus rules. But if this incentive was removed, most (if not all) node operators would just run on a block-header-only diet.
For users, what matters to them is to be able to unlock coins (provided nodes didn't prune their UTXOs). This process involves having access to the previous transaction outputs which can be fetched by nodes and verified using the Merkle tree.
Therefore with Bitcoin, there is this distinction made between what is enforced by the protocol and therefore cannot be changed without altering Bitcoin's design and functioning, and what works through financial incentives which, if disincentivised, wouldn't break the protocol.
These mechanics through incentives is what can be altered and counterbalanced. This is where consensus and law can easily act upon.
Breaking Bitcoin's financial incentives
We have seen that Bitcoin's financial incentive mechanisms do not break Bitcoin's protocol nor its functioning. Let's focus on how those incentives can be rebalanced.
Miners (which are nodes) could agree through consensus that it is in their interest to blacklist and prune specific transactions or transaction outputs, for reasons that can be incentivised by:
- Court order.
- Consuming too much disk space - such as storing a pile of useless data contained in buried transactions of the blockchain.
- Direct and strong financial incentives such as Satoshi coins which (almost) nobody wishes to see move.
For this last listed point to occur, they could decide to use a modified version of the software that simply fails when those blacklisted transaction or transaction outputs are encountered. Meaning that the UTXOs will suddenly become unspendable, therefore prunable, therefore inaccessible when pruned. And since it is done through consensus by the majority of the network, nodes which have not opt-in will either fork away when including into blocks spending transactions that use blacklisted UTXOs or they will have to adopt the new consensus. This second choice is strongly in their own financial interests!
Let's focus on Law, because it is one of the most interesting use cases, in my opinion.
Law wouldn't require 100% of nodes agreement, as long as the majority of nodes agree (consensus). The reason international court orders will work in the case of Bitcoin as opposed to court orders to block ThePirateBay for example (and similar failed court orders) is because:
- Nodes are/will be established businesses. They will be strongly incentivised to comply, otherwise: jail time, business closed, fines... which is probably better to avoid for just a couple of satoshis earned through transaction fees...
- As long as the network has a majority of nodes that comply, the consensus is automatically enforced.
In the case of ThePirateBay law failed because it required shutting down every single server or blocking them from every single ISP. In the case of Bitcoin, Law would only require the majority of nodes to comply.
One of the concerns you might think of is the case of disagreements between countries. Does it mean we would have a Bitcoin in China, a Bitcoin in the U.S., a Bitcoin in Russia, etc. due to failed consensus? I believe this is very unlikely to happen because, to be effective on the ban, governments will require the majority of nodes to agree, which is a decision that will be agreed upon prior to issuing court orders (if done properly). Also, at this stage we can only speculate on Bitcoin's future, but governments that decide to try enforcing consensus on their own country's nodes will shoot their own economy in the foot. Those governments will still have the economic incentive to remain on the main blockchain used by everyone else globally. But again, this assumes a high level of maturity where Bitcoin is used globally and is the international ledger for global economy and exchanges. Which is clearly not where we are at now.
Finally, international law can also be used to force consensus to prune any illegal/illicit data from the blockchain. Which will make the data's transaction outputs inaccessible from a majority of nodes. However, you might still be able to find that data on nodes that either don't comply with the law and kept the transaction on record (they would still need to consider those transactions as blacklisted to validate incoming blocks properly though). But that wouldn't be any different from the current functioning of our Internet... Of course, there will also be nodes used for record keeping (held by legal entities for forensics purposes) and most likely nodes that will sell access to rare data that is difficult to find because pruned.
Bitcoin's consensus will eventually be shaped according to the global legal frameworks it operates within.
Conclusion
This was a very long article. I have tried to keep it as close as possible to my investigation methodology. Which hopefully helped demonstrate how I came to the conclusion that any data on Bitcoin's blockchain is prunable and therefore not permanent.
In this article we have seen that there are different levels of permanency because there are different levels of incentives for nodes to leave transactions accessible to users. But we also saw ways to counterbalance those incentives which would force nodes to operate within an agreed consensus and within the framework of the law, international law.
I believe the most important lesson is that if you wish your transactions (and therefore data) to remain accessible everywhere, you need to give node operators something they value in the long term. But remember, if the transaction is or becomes too costly to keep compared to their return on investment, they might just decide (through consensus if needed) to wipe it off.
Here are my main guidelines to reduce the likelihood of your data being pruned:
- Move your coins, move your data. Show there is activity. So that nodes understand the data moves and therefore transaction fees are likely to drop frequently. So they won't be incentivised to prune any of your UTXOs.
- Use encryption, so your content remains neutral and cannot easily be identified by nodes. Otherwise they may judge that your content is illicit (although, I'd really be curious to see how Chinese nodes react to Winnie the Pooh pictures or references embedded within transactions).
- Don't upload illicit or illegal data.
- Don't bloat the blockchain with large valueless chunks of data. As it might cost more for node operators to keep them stored than they will earn through transaction fees if the transactions are ever spent.
- Incentivise node operators with unspent transaction outputs and when possible, insert your data within UTXOs.
About this last point, Bitcoin SV is not there yet in terms of restoring the original Bitcoin design. For this, you will need to wait until next year with the Genesis upgrade to allow for push data operations with non-standard transactions.
 Craig Wright (Bitcoin SV is Bitcoin.)
Craig Wright (Bitcoin SV is Bitcoin.)
Hopefully, the Bitcoin developers will do a good job at it (big shoutout to Steve Shadders and his team) and Bitcoin will finally be used for more than just moving coins around. Restoring the original unlimited version of Bitcoin is key for its success!
Next. OP_PUSHDATA4. That is All.
— _unwriter (@_unwriter) January 23, 2019
I also wish to end this article on two open questions: Will nodes become the great filters of Bitcoin? And when will the first act of Law to prune illegal transactions occur?
